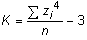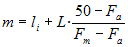|
|||||||||||||||
| Pràctica |
|
|
|
|
|
|
|
|
Exercicis
|
|
|||||
|
|
|||||||||||||||
| Estadística descriptiva |
|
||||||||||||||
|
El propòsit d'aquest document és comentar breument les tècniques i els conceptes de l'estadística descriptiva elemental que són, principalment:
Conceptualment, cal distingir amb claredat, per al treball amb les variables numèriques, si es tracta d'una variable discreta o bé d'una variable contínua, tot i que l'ús de programaris, com és ara Excel, fa que moltes vegades aquesta distinció i algunes de les reflexions que es fan seguidament siguin supèrflues , perquè l'ordinador treballa sempre que pot amb totes les dades recollides. |
|||||||
| Taules i gràfics | |||||||
|
Per a una variable numèrica discreta es comença per fer una taula de freqüències on s'hi fan constar, per cada valor de la variable, les freqüències absolutes i relatives (expressades aquestes en tant per u o en tant per cent) i també les freqüències acumulades (freqüències dels valors observats menors o iguals que el que defineix aquella classe). El diagrama més emprat per a la descripció
d'aquest tipus de variables és el diagrama de barres.
És interessant incloure dues escales de graduació a l'eix vertical
-absoluta i percentual- a l'hora de representar els diagrames de barres.
Si la variable que volem descriure és numèrica convé
graduar l'eix horitzontal de manera consistent. Per treballar amb una variable numérica contínua hem de reflexionar al voltant del concepte de precisió en el procés de mesura. Per a aquests tipus de variables, no tenen sentit les expressions del tipus X = a, sinó que sempre s'ha de pensar en valors localitzats en un interval. Per exemple, si diem que una persona pesa 65 quilos vol dir que hem arrodonit la mesura als quilos; en realitat, observarem aquest valor per a totes les persones en què el seu pes estigui comprès entre 64,5 kg i 65,5 kg. Com que, per altra banda i tot i els arrodoniments, acostuma a ser bastant àmplia la gamma de valors que pot prendre una variable contínua, aquests valors s'agrupen en classes, definides per intervals, que és recomanable que siguin tots de la mateixa longitud. El procés d'agrupació en classes és la idea conceptual que distingeix el treball amb varibles contínues o amb variables discretes. Ara bé, aquest procediment és del tot subjectiu i és difícil dir quants i quins són els "intervals ideals" per a l'estudi d'una variable. En la taula de valors d'una variable contínua convé indicar:
|
|||||||
| Paràmetres estadístics | |||||||
|
El càlcul de paràmetres estadístics sorgeix de la necessitat de resumir un conjunt nombrós de dades numèriques en uns pocs paràmetres representatius. Distingim:
|
|||||||
| Paràmetres de tendència central | |||||||
| La moda | |||||||
Aquesta definició s'ha d'entendre en un sentit ampli: el que es procura indicar amb la moda és l'existència d'un valor que destaca molt per sobre dels altres. Si hi ha dos (o més) valors les freqüències dels quals siguin relativament semblants i destacades per sobre de la resta, es parla de distribucions bimodals (o multimodals). Aquest paràmetre és molt intuïtiu, però no acostuma a tenir transcendència estadística. Per altra banda el seu ús s'ha de limitar a variables qualitatives o discretes. L'Excel calcula la moda d'una variable contínua amb els valors individuals de les dades i llavors no acostuma a tenir cap significativitat. Si, en aquest cas, es vol considerar la moda s'hauria de començar per l'agrupació en classes i parlar llavors , més aviat, de la classe modal. |
|||||||
| La mitjana | |||||||
| La mitjana és el resultat de fer la suma de tots els valors observats de la variable numèrica i dividir pel nombre total d'observacions i és un paràmetre molt sensible a l'existència de valors extrems (a vegades dits anòmals o atípics) en la distribució. | |||||||
Per calcular la mitjana en una variable contínua:
|
|||||||
| La mediana | |||||||
|
|
Aquesta definició, que és la que empra l'Excel en tots els casos, necessita una petita matisació.
La definició de la mediana indica que és un paràmetre que, sobre tot per a conjunts molt nombrosos de dades (que és quan realment té sentit pràctic fer-ne el càlcul) no queda alterat pels possibles canvis de valor de les dades extremes de la distribució de frequències. Per això es recomana sovint per "prevenir" possibles errades en l'entrada de dades.
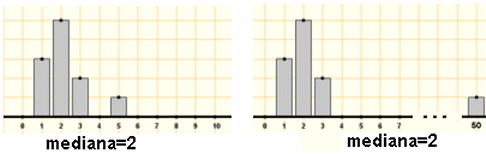
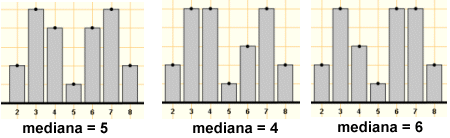
Ara bé, si es fa el càlcul de la mediana seguint la definició inicial en un conjunt de dades discretes, una variació en una sola dada de la distribució pot provocar un salt brusc en el valor de la mediana. Vegeu-ho:
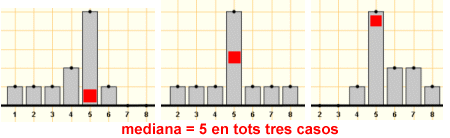
Per altra banda, en altres ocasions apareix el mateix valor de la mediana per a conjunts de dades ben diferents.
En aquesta darrera imatge, oi que estaria bé indicar d'alguna manera que la posició de la mediana en el conjunt de valors iguals a 5 és ben diferent? Això mateix escau quan es treballa amb variables contínues: hi ha moltes ocasions en què no es disposa de les dades inicials, sinó únicament d'un estudi que ja ens dóna les freqüències que corresponen a una determinada agrupació en classes. En aquest cas, es podria parlar simplement de la classe medianera, però, de fet, es pot precisar més i es defineix la mediana com el valor de la variable que correspon a una freqüència acumulada del 50 %, llegida sobre el polígon de freqüències relatives acumulades. Aquesta definició de la mediana (que, tanmateix, habitualment no està incorporat als programes estadístics d'ordinador) evita els salts bruscs de valor que hem comentat deguts a petits canvis en el valor d'una o algunes dada. Podeu clicar, si us interessa, sobre la icona d'ampliació que teniu a l'esquerra i veureu un exemple que mostra clarament la conveniència d'aquesta matisació i il·lustra aquest procediment per calcular la mediana per a variables numèriques contínues. |
||||||
| Estudi comparatiu de la mitjana i la mediana | |||||||
|
|
Per a la utilització de la mediana i de la mitjana com a paràmetres de centralització, hem de tenir ben present les idees següents:
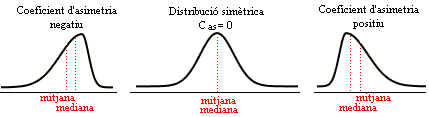
Una manera intuïtiva de mesurar el grau de simetria d'una variable numèrica és la de comparar els valors de la mediana i la mitjana. Efectivament, si la distribució és totalment simètrica, la mediana i la mitjana coincideixen i, en canvi, la distribució difereix més d'un model simètric com més distanciades estiguin la mediana i la mitjana, de tal manera que "la cua més allargada" es presenta cap al cantó de la distribució on es trobi la mitjana. Ara bé, cal tenir en compte que sempre que es fan càlculs per tal d'establir "la simetria" es fa amb la intenció de confrontar si el model normal (de què parlarem a bastament en mòduls més avançats) és o no un model consistent per a la població de la qual s'ha pres una mostra. Un conjunt de dades "és com és", el que ens preocupa en un treball estadístic rigorós és saber què en podem inferir per a la població. Mai hi ha criteris "absolutament segurs" en l'àmbit de la inferència estadística i menys per aquesta regla heurística que ara ens ocupa (comparació de la mitjana i la mediana en una mostra per tal d'inferir la simetria de la variable estudiada en la població.) Podeu ampliar l'estudi d'aquest tema si cliqueu a la icona d'ampliació. Pot ser interessant fer-ho en acabar de llegir tot el document de fonaments. |
||||||
| Estudi de la dispersió d'una distribució | |||||||
|
La moda, la mediana i la mitjana resulten insuficients si hom vol resumir en un únic paràmetre numèric el comportament global d'una distribució estadística. No hem pas de donar la raó als que posen en boca de l'estadística la frase que diu: "Si tu menges dos pollastres i jo no en menjo cap, és com si cadascú n'hagués menjat un". Convé mesurar d'alguna manera el grau de dispersió de les dades.
El valor d'aquest paràmetre està fortament influït per l'existència de valors atípics situats als extrems de la distribució, molt allunyats de la resta del conjunt de dades. Això el fa ben poc representatiu, de vegades, i és poc potent per mesurar el grau de dispersió de les dades d'una distribució estadística. |
|||||||
| La desviació estàndard o desviació tipus | |||||||
| Per quantificar el grau de dispersió d'un
conjunt de dades al voltant de la mitjana es pot pensar a sumar totes les
diferències de cada dada menys la mitjana, però el fet que
algunes diferències siguin positives i d'altres negatives fa que,
en sumar-les, s'anul·lin entre elles. No es tenen en compte les diferències,
sinó les magnituds. En aquest sentit, es treballa amb els quadrats
de les diferències (sempre positius) que s'acumulen per totes les
dades de la distribució.
El fet d'haver elevat al quadrat les diferències a l'hora de calcular
la variància, fa que la unitat amb què es mesura aquest
paràmetre sigui igual al quadrat de la unitat amb què es
mesuren les dades de la distribució. Per aquest motiu, es treballa
amb el paràmetre que resulta de fer l'arrel quadrada de la variància.
Aquest és el paràmetre més emprat com a eina d'anàlisi de la desviació d'una distribució. La desviació estàndard es mesura en les mateixes unitats que les dades de la distribució. També es considera a vegades el coeficient de dispersióper relativitzar la mesura de la dispersió d'una distribució de frequències prenent com a punt de referència el valor absolut de les dades de la distribució (representat per la mitjana). Amb aquest coeficient es fa avinent que no representa el mateix una desviació estàndard d'una unitat (per exemple) si la mitjana de les dades té un valor de 5 que si la mitjana de les dades té un valor de 500. En aquest cas la desviació estàndard seria pràcticament inapreciable en el conjunt de les dades i en l'altre seria molt important.
|
|||||||
| La desviació estàndard, la calculadora i l'estadística inferencial | |||||||
| Les calculadores científiques
que tenen mode de treball estadístic presenten dues funcions amb
el símbol de la desviació estàndard, sn
(o simplement s) i sn–1
(també designada com a s en alguns models).
Aquestes dues tecles donen dos paràmetres calculats amb fórmules anàlogues que difereixen només en el denominador de la fracció: mentre per a la primera dividim per n (nombre de dades), per a la segona dividim per n – 1.
La diferència entre els dos paràmetres és conceptualment molt important. Si volem fer una tasca d'inferència i intentar estimar paràmetres de la població a partir dels que hem observat en una mostra, es pot demostrar que la desviació tipus calculada amb denominador n – 1 a partir de les dades que tenim recollides en la mostra és un millor estimador de la desviació tipus de la població que no pas la calculada amb denominador n. La desviació estàndard calculada amb denominador n és qualificada pels manuals com a desviació estàndard poblacional o bé com a desviació estàndard no corregida, i la segona, la que es calcula amb denominador n – 1, s'anomena desviació tipus mostral o, de vegades, desviació estàndard corregida. A la pràctica
5 del mòdul 7 es treballa a fons aquest tema i es constata
que el millor paràmetre per fer estimacions és la
|
|||||||
| Estandardització de dades. Altres paràmetres estadístics | |||||||
| Per buscar un model
escaient per a una distribució estadística de dades interessa
sovint prescindir de la influència de les unitats amb què
estan expressades les dades. Per fer-ho es tenen en compte dues propietats:
A partir de les dues propietats comentades anteriorment es pot assegurar que:
|
|||||||
| Coeficient d'asimetria | |||||||
Com que la variable estandarditzada s'expressa sense unitats, això mateix succeeix amb el valor del coeficient d'asimetria. Quan la distribució és simètrica, Cas = 0, perquè els sumands positius es compensen amb els negatius; si el valor de Cas és proper a 0, es pot considerar un grau de simetria alt per a la distribució estudiada i, doncs, una versemblança del model normal si ens fixem només en la simetria. En canvi, si el Cas té un valor positiu gran, és que predominen els sumands positius en el sumatori que ens porta al valor de Cas ; aquests sumands corresponen als valors de la variable superiors a la mitjana. En aquest cas, en què predominen els valors allunyats de la mitjana cap a la dreta es diu que la distribució és esbiaixada cap a la dreta o que presenta "una cua" cap a la dreta. Semblantment, si el coeficient d'asimetria té un valor negatiu gran en valor absolut es diu que la distribució és esbiaixada cap a l'esquerra i, en aquest cas, el perfil presenta "una cua" cap a l'esquerra. La funció de l'Excel que calcula el coeficient d'asimetria és: =COEFICIENTE.ASIMETRIA(rang de dades) |
|||||||
| Coeficient de curtosi (grau d'apuntament) | |||||||
| De forma anàloga a allò
que hem vist per al coeficient d'asimetria, s'estudia la mitjana de les
quartes potències dels valors estandarditzats.
Es comprova que el paràmetre que resulta quan fem el càlcul
El coeficient que mesura el grau d'apuntament (semblantment al que passa
amb el coeficient d'asimetria) té com a finalitat principal la
comparació de les dades empíriques recollides amb un model
teòric, per sobre de tots els models donats per la distribució
normal, de la qual parlarem a bastament al llarg del curs. Per qualsevol
distribució que s'ajusti a un model normal es demostra que el sumatori
anterior val 3 i és per això que es dóna la definició
següent.
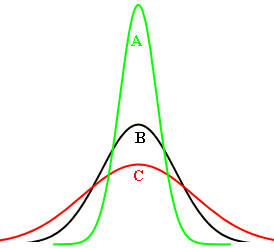
Si K té un valor proper a 0, la variable estudiada presenta un perfil d'apuntament semblant al de la distribució normal i rep el nom de distribució mesocúrtica, com és ara la B del gràfic següent (corba negra): Si K té un valor positiu gran, el perfil de la variable tindrà cues llargues o, equivalentment, una punxa molt pronunciada a la part central si ho comparem amb la distribució normal estàndard. Aquest tipus de distribucions s'anomenen leptocúrtiques. N'és un exemple la distribució de perfil A al gràfic (corba verda). Finalment, si K és molt negatiu, el perfil de la variable té molt poc apuntament i rep el nom de platicúrtica, com és ara la C del gràfic (corba vermella). Tanmateix hi ha altres condicionants que afecten el valor del coeficient de curtosi i el fan poc intuïtiu. La funció de l'Excel que calcula el coeficient de curtosi és =CURTOSIS(rang de dades ) |
|||||||
| Anàlisi exploratòria de dades (AED) | |||||||
|
Sota aquesta denominació s'agrupen un conjunt de procediments, relativament «moderns» i molt emprats en els tractats d'estadística aplicada a les ciències socials, potser pel fet que en la seva presentació no intervenen recursos matemàtics elevats. Aquestes tècniques tenen com a objectiu una visualització ràpida i global de les dades que, de fet, haurien de ser prèvies a altres estudis més aprofundits. Hem definit uns paràmetres de tendència central: la mitjana com a paràmetre uniformitzador i la mediana com la dada que ocupa la posició central de la distribució si posem per ordre creixent els seus valors i hem comentat que ambdós paràmetres resulten insuficients per tenir una idea del comportament global de la distribució de les dades, de la dispersió amb què les observem. És per això que es defineix la desviació estàndard com a paràmetre numèric per mesurar el grau de dispersió de les dades. A partir de la mediana es defineixen tot seguit els quartils i l'amplitud interquartíl·lica en el camí d'arribar a una descripció més detallada del repartiment dels valors de la distribució al llarg de tota l'amplitud de valors. |
|||||||
| Els quartils i l'amplitud interquartíl·lica | |||||||
|
|
La mediana d'una distribució estadística divideix la relació ordenada dels seus valors en dues parts que tenen el mateix nombre de dades. La idea intuïtiva dels quartils correspon a dividir la distribució ordenada en quatre parts. S'anomenen així:
Tot i que la idea intuïtiva és ben clara, a l'hora de fer el càlcul dels quartils no hi ha un tractament unívoc per part dels programes estadístics d'ordinador. Les diferències es constaten quan la distribució té poques dades i en canvi no són apreciables si el conjunt de dades és força nombrós. Això ens porta necessàriament a un comentari: si hi ha poques dades potser se'n pot fer una anàlisis individualitzada; no calen paràmetres descriptius! Podeu accedir a un apartat d'ampliació que explica com calcula els quartils el programa Excel i la seva relació amb els percentils i les dades que corresponen a un determinat percentatge. Per a les variables contínues es pot fer un tractament conceptual semblant al de la mediana, que podeu consultar també com a ampliació. Ara bé l'Excel fa sempre el càlcul dels quartils amb la consideració de variable numèrica discreta és a dir que, si es tracta d'una variable numèrica contínua, té en compte el valor de totes i cadascuna de les dades. No solament l'amplitud sinó que la consideració conjunta dels quartils, la mediana i l'amplitud serveixen com una eina d'anàlisi important de la dispersió de dades de la distribució. Aquest estudi es plasma en els diagrames de caixa, que estudiarem tot seguit. |
||||||
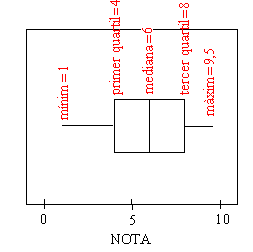
| Diagrama de caixa (box-plot) | |||||||
|
|
S'anomena diagrama de caixa o, en la denominació inicial Box-and-whisker plot, textualment diagrama de caixa i bigotis, una representació gràfica, introduïda per G. E. P. Box en el marc de l'anomenada anàlisi exploratòria de dades, que es pot elaborar després de localitzar les dades extremes d'una distribució estadística i calcular els valors dels quartils, amb la finalitat de fer visual la posició relativa d'aquests valors i, doncs, donar una idea de la dispersió que presenta la distribució de les dades al llarg del rang. Com a primera idea, per construir un diagrama de caixa dibuixarem un eix graduat amb els valors de la variable i, referit a aquest eix, un rectangle de base igual al segment que separa el primer i el tercer quartil, partit en dos per una línia feta pel valor de la mediana. A banda i banda del rectangle es dibuixen uns segments (cues o bigotis) que, en una abasten tota l'amplitud o rang de la distribució. És clar que cal acompanyar el diagrama de caixa d'un eix graduat segons els valors que pot tenir la variable i també és important
|
||||||
|
La longitud de la caixa central (amplitud interquartíl·lica, AIQ) és molt important en la construcció dels diagrames de caixa i en l'anàlisi de la distribució que es vol visualitzar. Aquesta longitud, relativitzada en el context de les dades de la distribució, ens explica com de juntes estan les dades centrals i per això, com ja hem dit, pot ser entès com un paràmetre de dispersió i s'empra també per caracteritzar les dades atípiques. En el treball estadístic convé distingir especialment aquelles
dades que s'aparten significativament de la resta de dades de la distribució.
Aquesta definició és poc precisa, perquè, de fet,
interessa sobretot des del punt de vista intuïtiu: no deixa clar
què s'ha d'entendre per "apartar-se significativament" de la resta
de dades. Quan en una distribució estadística apareixen
dades anòmales, s'ha d'estudiar molt bé si poden ser degudes
a errors comesos en el procés de recollida de dades: errors de
transcripció, errors a l'hora de fer les mesures, etc. Si realment
es confirma que s'ha produït algun error d'aquest tipus, cal eliminar
aquestes dades o, si és possible, esmenar l'error. En qualsevol
altre cas, no és lícita l'eliminació de les dades
atípiques tot i que s'ha de tenir molt present com poden influir
en l'estudi. En els diagrames de caixa de les distribucions que contenen dades anòmales, aquestes es representen mitjançant punts aïllats i els "bigotis" arriben per un costat a la més petita de les dades no atípiques i per l'altre costat a la més gran d'aquestes dades no atípiques. Per tant, com a màxim, la longitud dels bigotis més la caixa és de 4 amplituds interquartíl·liques. En el diagrama que hem donat com a exemple no apareixen valors atípics però sí que en veureu en els que es mostraran seguidament. Nota: En la pràctica 6 no es tindrà en compte aquesta distinció i es dibuixaran els "bigotis" des del mínim per un costat fins al màxim per a l'altre. Tanmateix si alguna de les lectores o algun dels lectors té coneixement del disseny de macros amb Excel ho pot intentar! |
|||||||
| Diagrames de caixa múltiples | |||||||
|
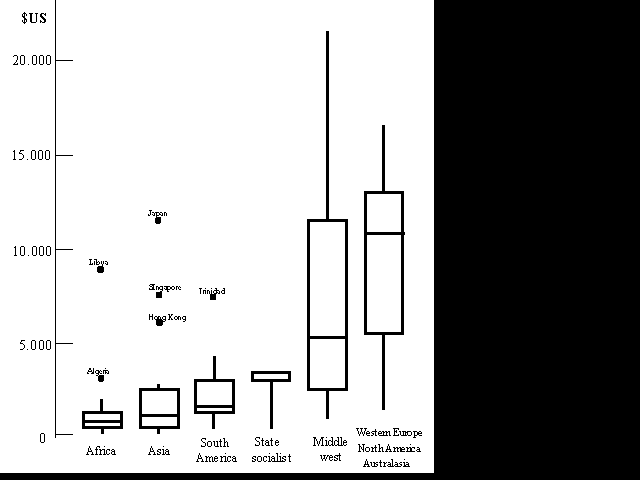
L'ús fonamental dels diagrames de caixa no el trobem en la descripció d'una variable sinó com a element intuïtiu de contrast entre distribucions de variables estadístiques. Efectivament, si imaginem juxtaposats dos diagrames de caixa relatius a variables anàlogues (per exemple, les notes d'un altre examen en el mateix grup classe que l'anterior), veurem que efectivament això permet una comparació global i ràpida entre la distribució de dades de dues variables anàlogues definides sobre la mateixa població. Semblantment, si hom ha de comparar dues o més distribucions d'una mateixa variable mesurada sobre poblacions diferents (o sobre diferents grups estadístics en una mateixa població), la visualització simultània dels corresponents diagrames de caixa sol aportar una informació molt valuosa. Seria un exemple d'aquesta darrera situació la comparació de les notes d'un mateix examen en dos grups classe o bé el que es mostra seguidament.
Diagrama de caixes múltiple corresponent
als valors del producte nacional brut per càpita Plantegem-nos algunes qüestions sobre aquestes dades:
Les qüestions anteriors i moltes d'altres es poden respondre amb claredat a la vista dels gràfics dels diagrames de caixa.
|
|||||||
|
|
|||||||
| Ampliacions, aclariments i comentaris | |||||||
|
Podeu consultar, si us interessa, un exemple que mostra clarament la conveniència
d'una matisació conceptual per al càlcul de la mediana per
a les variables contínues
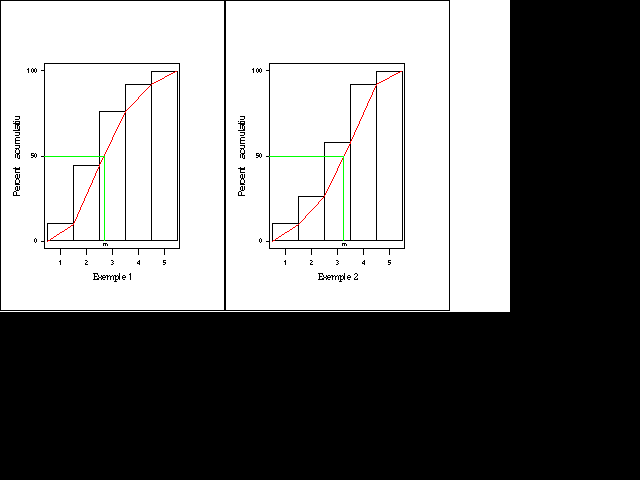
Vegeu les taules de freqüències de dues variables que anomenarem EXEMPLE1 i EXEMPLE2 on es mostren els aspectes comentats fins ara.
Tots dos exemples corresponen a conjunts de 50 dades; en tots dos casos la "classe medianera" és la que té com a marca de classe 3.0, perquè és aquella en què la freqüència relativa acumulada supera el 50 %. Tanmateix, aquests dos exemples que acabem de presentar tenen uns polígons de freqüències relatives acumulades ben diferents. La forma de les poligonals que s'han dibuixat sobre els histogrames de freqüències acumulades (en vermell) provenen del fet de suposar els elements de cada classe uniformement repartits al llarg dels corresponents intervals. Si imaginem les 50 dades de cada conjunt distribuïdes i ordenades d'aquesta manera es veu força clarament que, tot i que els valors centrals d'una distribució i de l'altra queden a la classe del 3.0, en el primer cas queden al principi de la classe i en el segon cas al final. Aquesta idea ens suggereix la conveniència d'ajustar més el valor de la mediana. Per materialitzar l'observació de la mediana com el valor al qual li correspon la freqüència acumulada del 50 % s'han traçat les línies en verd sobre els gràfics anteriors:
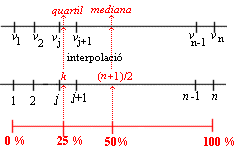
Podeu veure que la mediana del primer conjunt de dades mesurada sobre el gràfic és, aproximadament, 2.7, i la del segon conjunt de dades és 3.2, valors que concreten allò que ja s'ha dit: en el primer cas, la mediana queda al principi de l'interval de classe, i en el segon cas, al final. Recordeu que l''exemple que s'acaba de fer segueix una idea conceptual (teòrica) associada a la tabulació d'una variable contínua i que l'Excel no calcula la mediana d'aquesta manera, sinó a partir de les dades originals, i no incorpora de manera clara el treball a partir d'una taula de dada/freqüència. Si es fa un estudi mitjançant la semblança de triangles en el rectangle corresponent a la classe medianera, es pot establir una fórmula per al càlcul de la mediana com a variable contínua, que es pot escriure així:
Si s'aplica aquesta fórmula, naturalment més precisa que l'observació dels gràfics, als dos exemples anteriors, resulta: Exemple 1: m = 2,69 Exemple 2: m = 3,25 |
|||||||
|
|
|||||||
|
Càlcul dels quartils a l'Excel. Comparació amb altres programes Seguint amb la visió intuïtiva amb què s'han presentat els quartils, es podria dir que el primer quartil és la mediana de la distribució de dades formada pel conjunt del 50 % de dades inferiors i semblantment el tercer quartil és la mediana del conjunt format pel 50 % de dades superiors. Ara bé, aquesta visió intuïtiva no és del tot rigorosa i porta a diferents criteris sobre "què s'ha de fer amb la mediana" si inicialment hi havia un nombre imparell de dades. La posem en les "meitats de la distribució" o no? Segons que es decideixi una cosa o una altra els valors dels quartils seran diferents i la idea de repartir les dades en "quatre quarts" a vegades no semblarà prou reeixida intuïtivament. Com a idea general de totes les referències que es poden consultar per a calcular els quartils podem dir que es parteix dels valors ordenats de la distribució
Per buscar els "quartils" del conjunt {1, 2, ..., n–1, n}, és a dir per dividir el conjunt de dades "en quatre parts", i tot seguit obtenir els quartils de la distribució de dades l'Excel procedeix així:
Vegem un exemple amb el conjunt de 10 dades (que es donen ja ordenades) {2, 5, 8, 8, 10, 12, 12, 14, 16, 18}.
En aquest apartat d'ampliació és interessant completar encara una mica més el tema i generalitzar la idea de quartils a la d'un percentil qualsevol en una distribució. És del tot clar, llavors, que el primer quartil correspon al percentil del 25 %, la mediana correspon al percentil del 50 % i el tercer quartil correspon al percentil del 75 %. El procediment de l'Excel per calcular un percentil segueix la idea exposada en la il·lustració anterior (amb la interpolació inclosa) però amb el percentatge que interessi enlloc del 25 %.
|
|||||||
|
|
|||||||
| En el cas de les variables
contínues, es pot fer per als quartils un tractament conceptual semblant
al de la mediana
Es pot establir també una fórmula, derivada de l'aplicació de la semblança de triangles, per a cada quartil. La primera cosa que cal fer, en cas de tenir únicament una tabulació de dades d'una variable contínua, és localitzar les classes a què pertanyen els quartils. Seguidament una fórmula com la que s'ha donat per a la mitjana però substituint-hi el 50 per 25 en el cas del primer quartil i per 75 en el cas del tercer ens dona els valors més precisos per a aquests quartils. |
|||||||
|
|
|||||||
|
Sobre la comparació de la mitjana i la mediana de la mostra per intentar inferir la simetria de la variable estudiada en la població.
|
|||||||
|
|
|||||||
|
Per consultar exemples de diagrames de caixa i confrontar possibles diferències si es fa el càlcul a partir de la definició inicial o per interpolació. Ja s'ha comentat la possibilitat de "salts" en els valors de la mitjana (i semblantment en els quartils) si es calcula amb la definició intuïtiva. Ara bé, si imaginem que partim d'un histograma corresponent a un conjunt gran de dades d'una variable contínua i fem el càlcul de la mediana per interpolació s'aconsegueix una matisació en el valor de la mediana que evita els "salts bruscs de valor" i, alhora, explica amb més precisió la posició de la mediana. Si fem el càlcul de la mediana d'una manera o d'una altra, això afecta molt la forma dels diagrames de caixa. L'aplicació didàctica (amb dues versions) que s'ha presentat en l'ampliació anterior permet construir de manera interactiva el vostre propi diagrama de barres o histograma i confrontar-lo amb el diagrama de caixa corresponent (i, per tant, visualitzar els valors de la mediana i els quartils.)
|
|||||||
|
|
|||||||
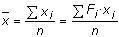
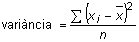
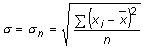
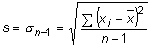
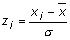
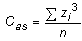
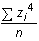 té relació
amb el grau d'apuntament (o sigui amb el grau de punxa del perfil
corresponent o, mirat des de l'altre punt de vista, amb el caràcter
més o menys aplanat d'aquest perfil).
té relació
amb el grau d'apuntament (o sigui amb el grau de punxa del perfil
corresponent o, mirat des de l'altre punt de vista, amb el caràcter
més o menys aplanat d'aquest perfil).